Using python to combine pdfs systemically saved in file folders
I needed a way to combine multiple pdfs stored in various folders quickly so I wrote a program to do so.
Background
I’m currently invovled in a phased construction project as the construction manager at risk. We are nearing the end of our third phase and entering into our fourth phase. The fourth phase is the construction of a kitchen, administrative offices, and a gymnasium. The fourth phase is currently being desinged and thereafter will be solicited for bid, negotiated, and built.
We are nearing the end of the design process and are entering into solicitations. As the construction manager, we are responsible for segregating the overall project into its various scopes and soliciting it to subcontractors.
Now, keep in mind. Any segregation we make must still equal to the entirety of the project before we segregated it. Otherewise, we assume the responsibility for the cost. And because it’s ultimately not me footing the bill if I drop a scope. My boss has asked for me to prepare drafts of various bid packages, also referred to as scopes, for review and approval. As a result, I have found myself frequently having to combine loose pdfs stored in various folders into a binder and print them out. What a pain!
Problem
I frequently have to combine loose pdfs stored into various folders into a binder and print them out.
Solution
Write a python script to:
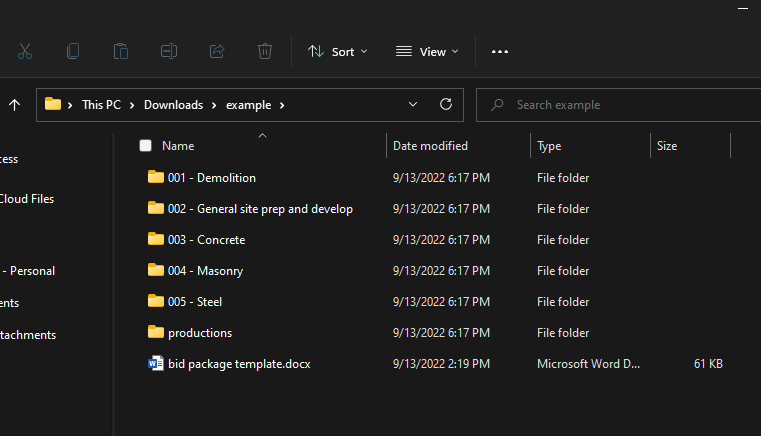
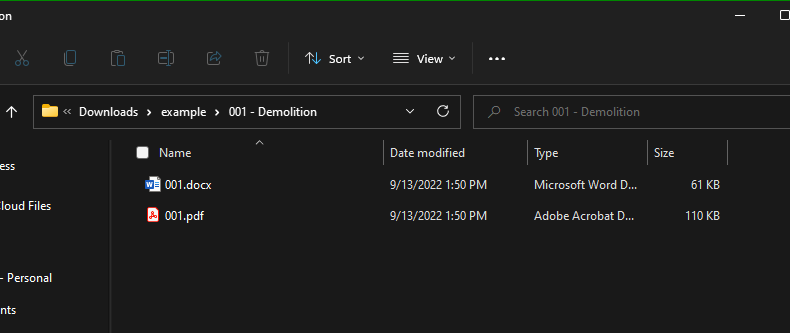
Access main folder housing sub-folders containing a single pdf and a word document.
Iterate over subfolders.
Search within folder for ‘.pdf’ file types.
Copy file if found to new folder for future compilation into a binder.
Change to new folder.
Prepare binder.
Parent folder
Sub folder and contents
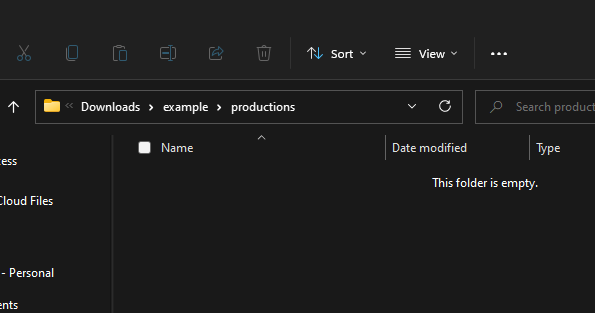
Production folder. Note: this folder is empty because we haven't ran code to copy loose pdfs and produce binder
Here is the python script
import os
from PyPDF2 import PdfMerger
import shutil
#access parent folder
os.chdir(r'C:\Users\Beaufuh\Downloads\example')
#declare parent folder for future call
parent_dir = os.getcwd()
#iterate over contents in parent folder
for i in os.listdir():
#filter iteration from going over productions folder
if not i == 'productions':
if "." not in i:
os.chdir(parent_dir+'//'+str(i))
for j in os.listdir():
if '.pdf' in j:
#if pdf instead of .docx copy file to production folder
shutil.copy(os.getcwd()+'//'+str(j), r'C:\Users\Beaufuh\Downloads\example\productions')
#declare list for housing pdfs to be compiled
pdfs = []
#change to production folder
os.chdir(r'C:\Users\Beaufuh\Downloads\example\productions')
#iterate over production folder contents
for i in os.listdir():
if '.pdf' in i:
#if file is type pdf add to list of pdfs to be combined
pdfs.append(str(i))
#method call to PyPDF2 object
merger = PdfMerger()
#iterate over items in pdf list prepared for binder
for pdf in pdfs:
#add to binder
merger.append(pdf)
#write binder to file system
merger.write('binder.pdf')
#save
merger.close()
What is the result of this?
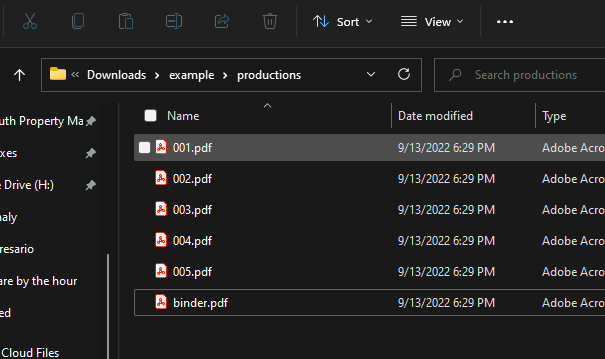
After running our script, our productions folder that was previously empty now contains a copy of each loose pdf and a binder that was programmatically created from all of the loose pdfs.
As always, s/o to python for automating the boring stuff. 😁🚀🔥